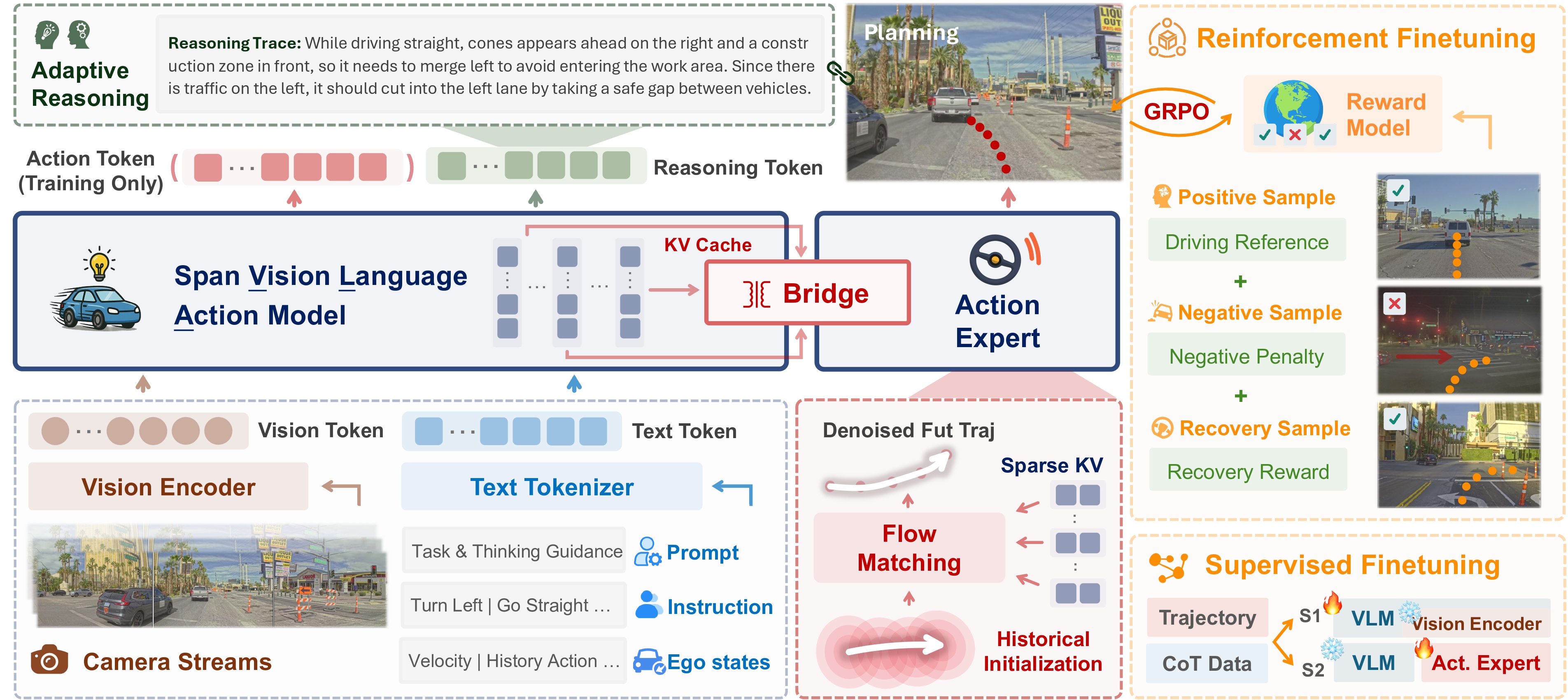
Vision-Language-Action (VLA) models offer a promising autonomous driving paradigm for leveraging world knowledge and reasoning capabilities, especially in long-tail scenarios. However, existing VLA models often struggle with the high latency in action generation using autoregressive generation framework and exhibit limited robustness.
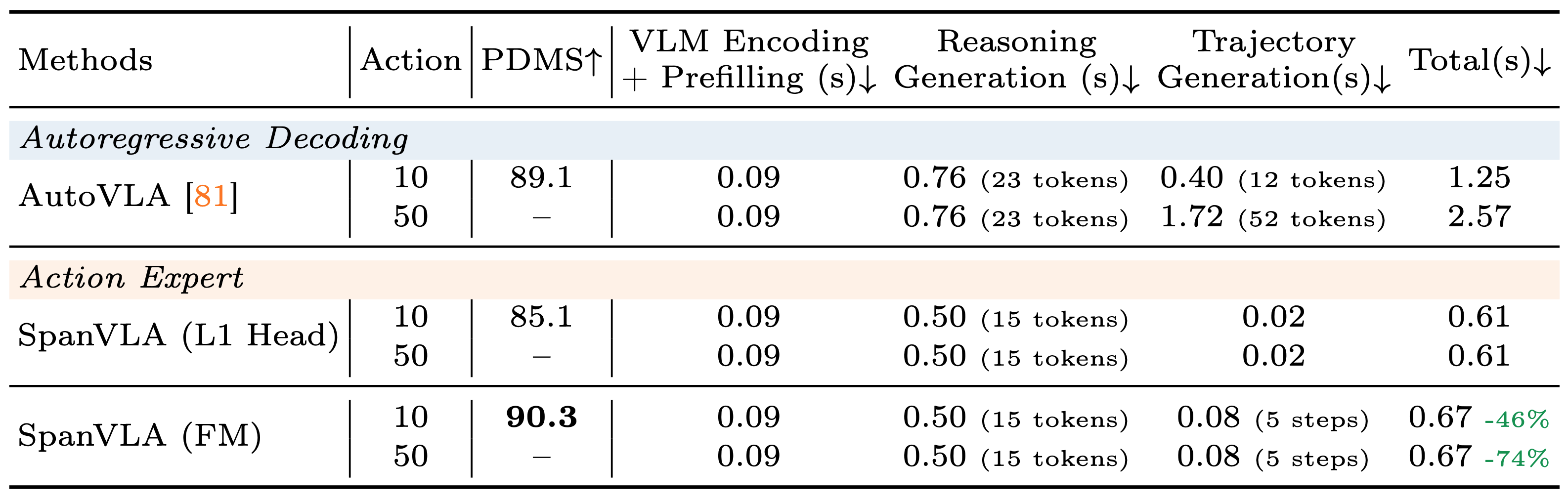
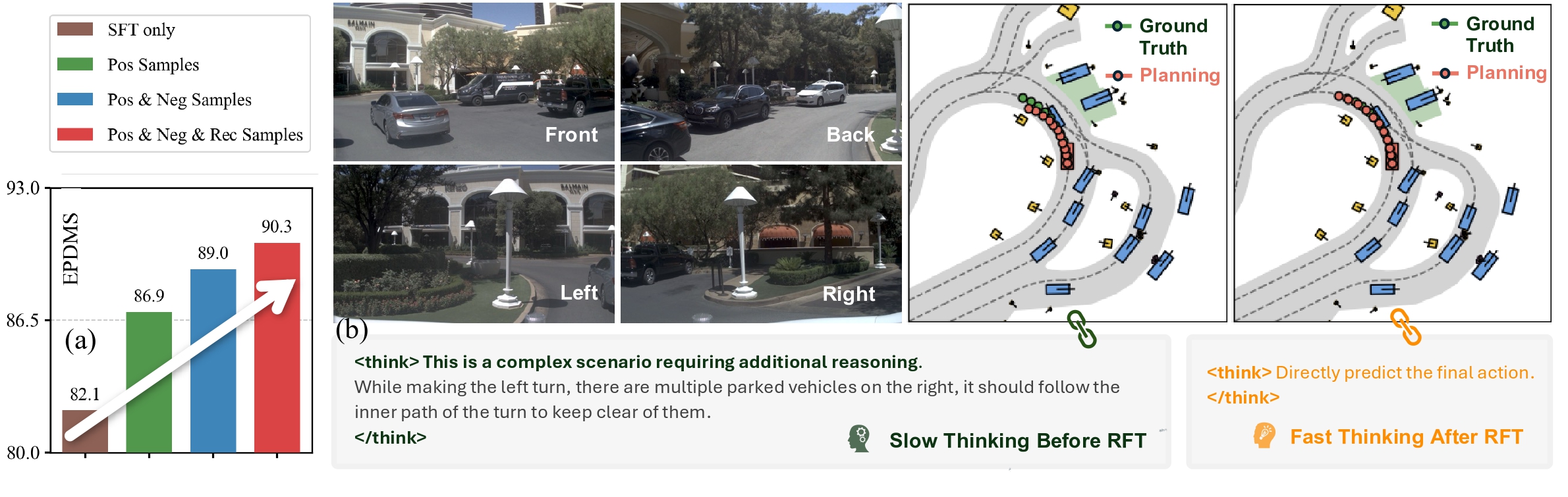
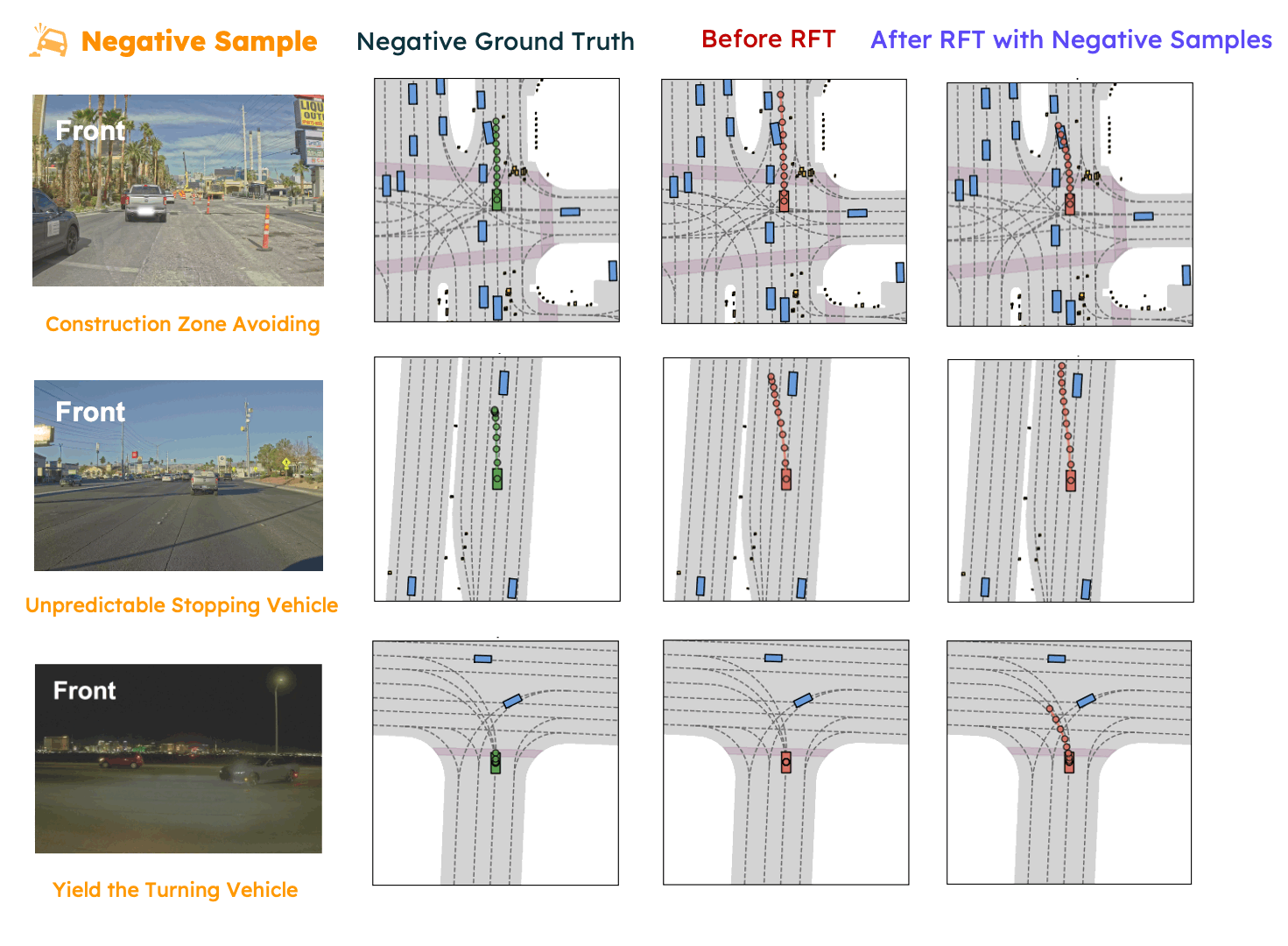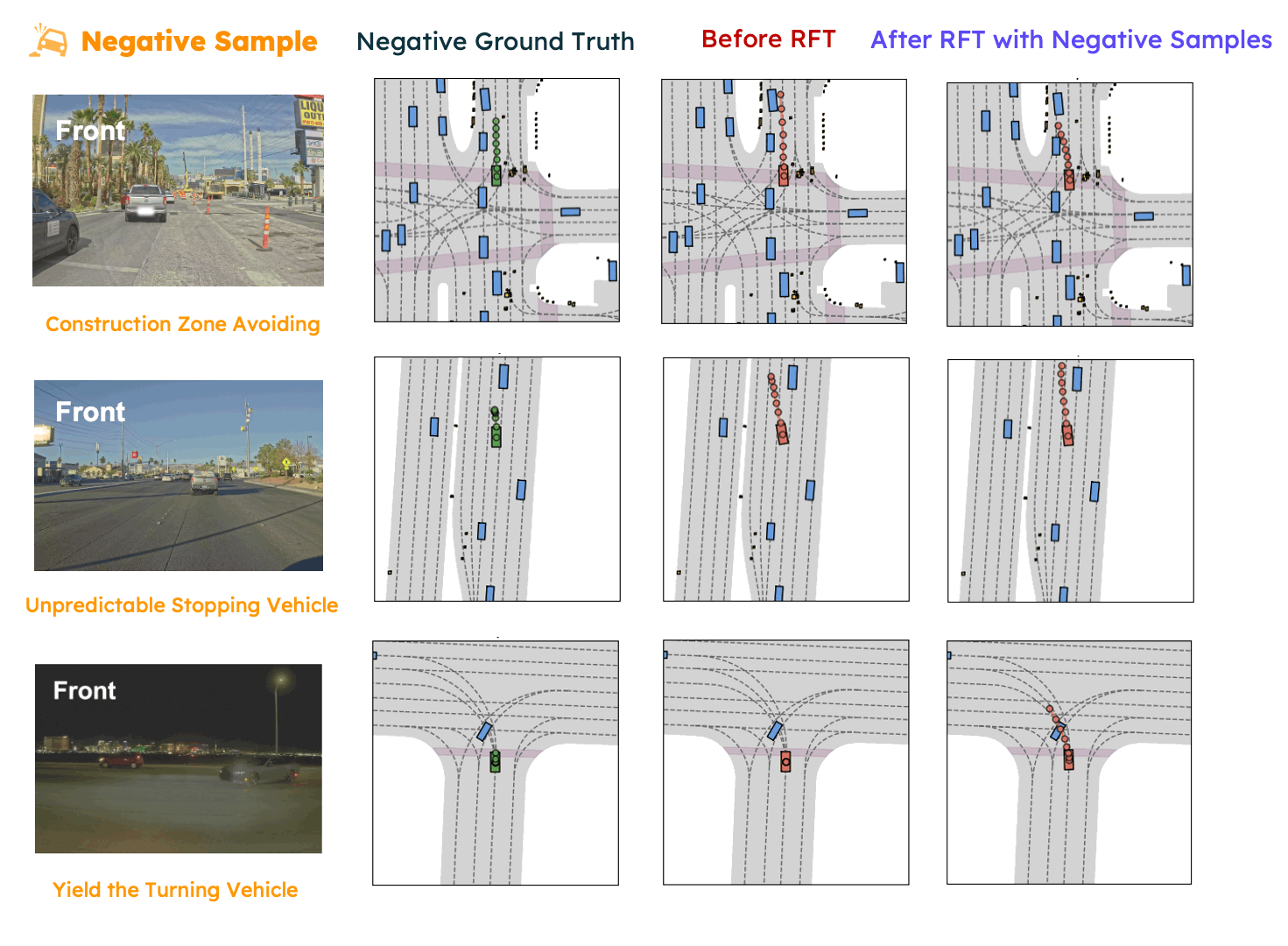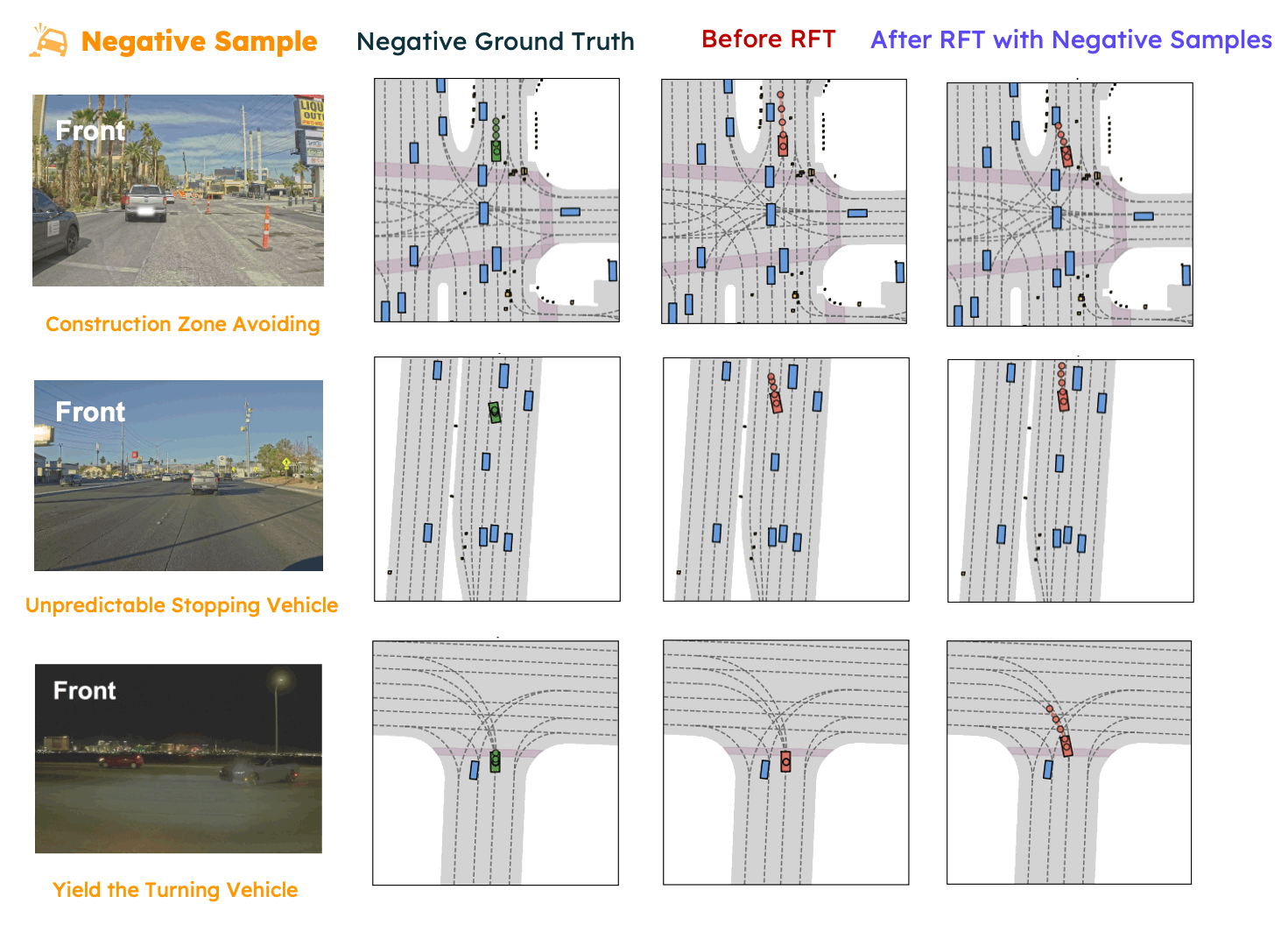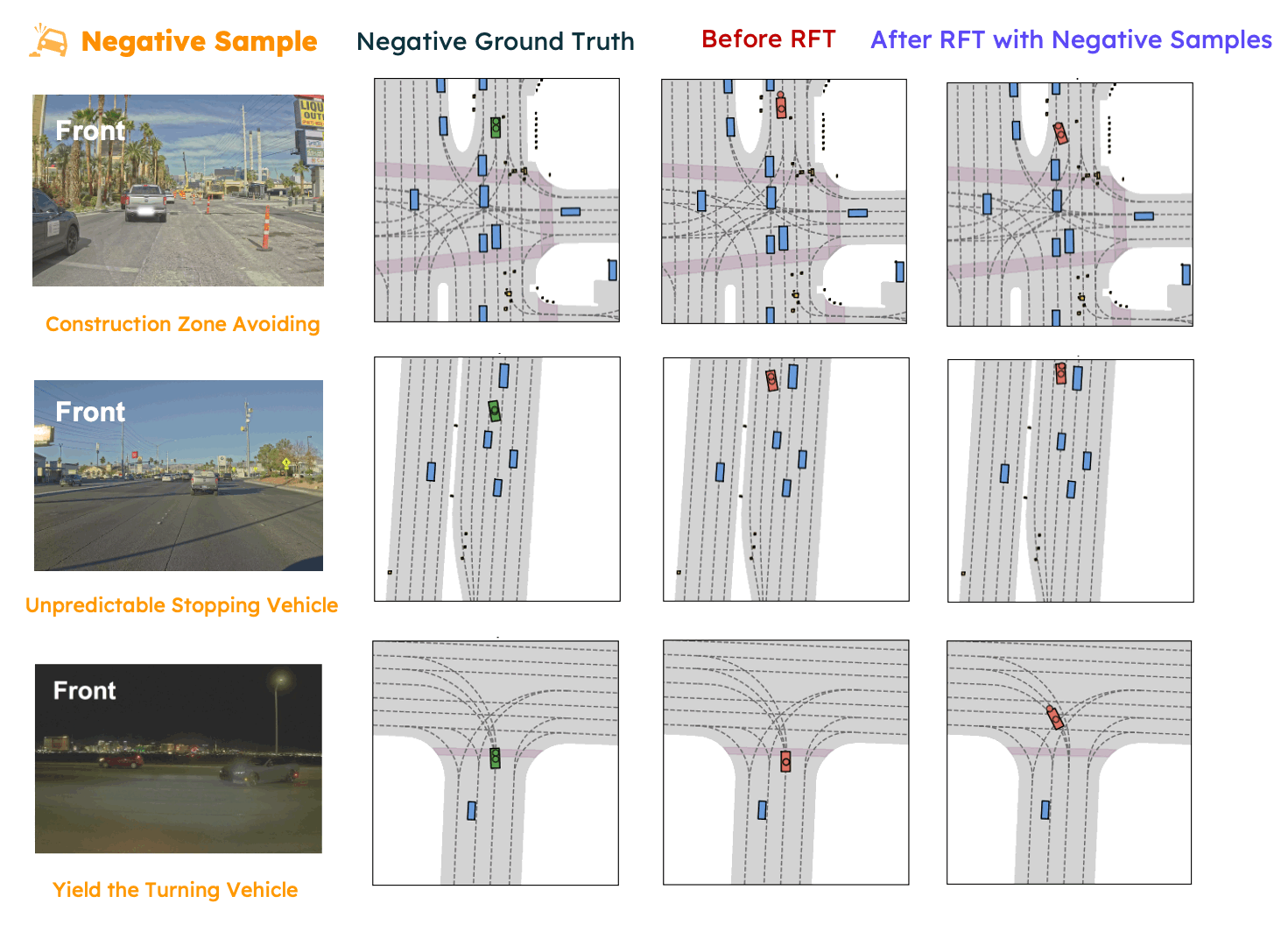
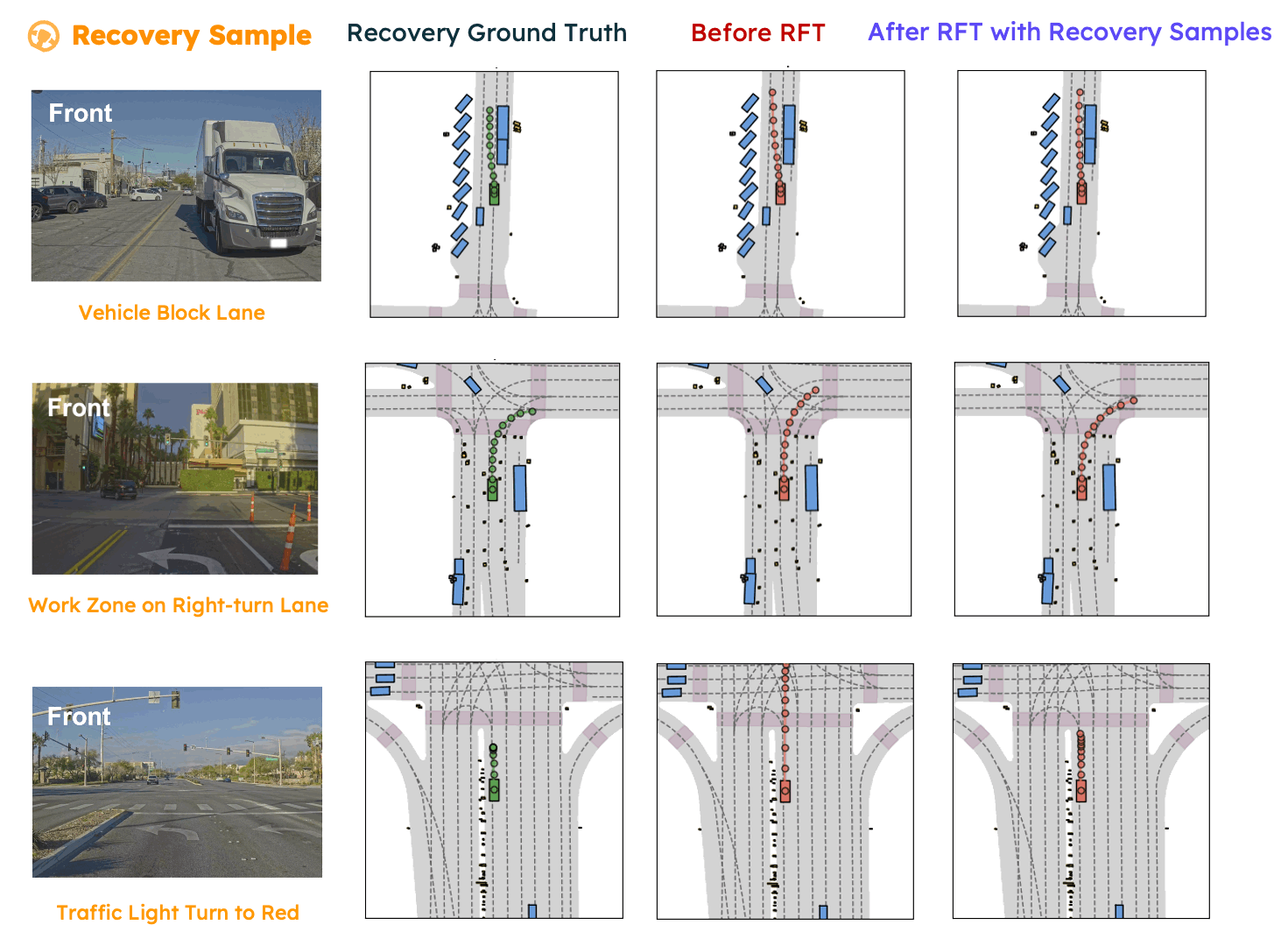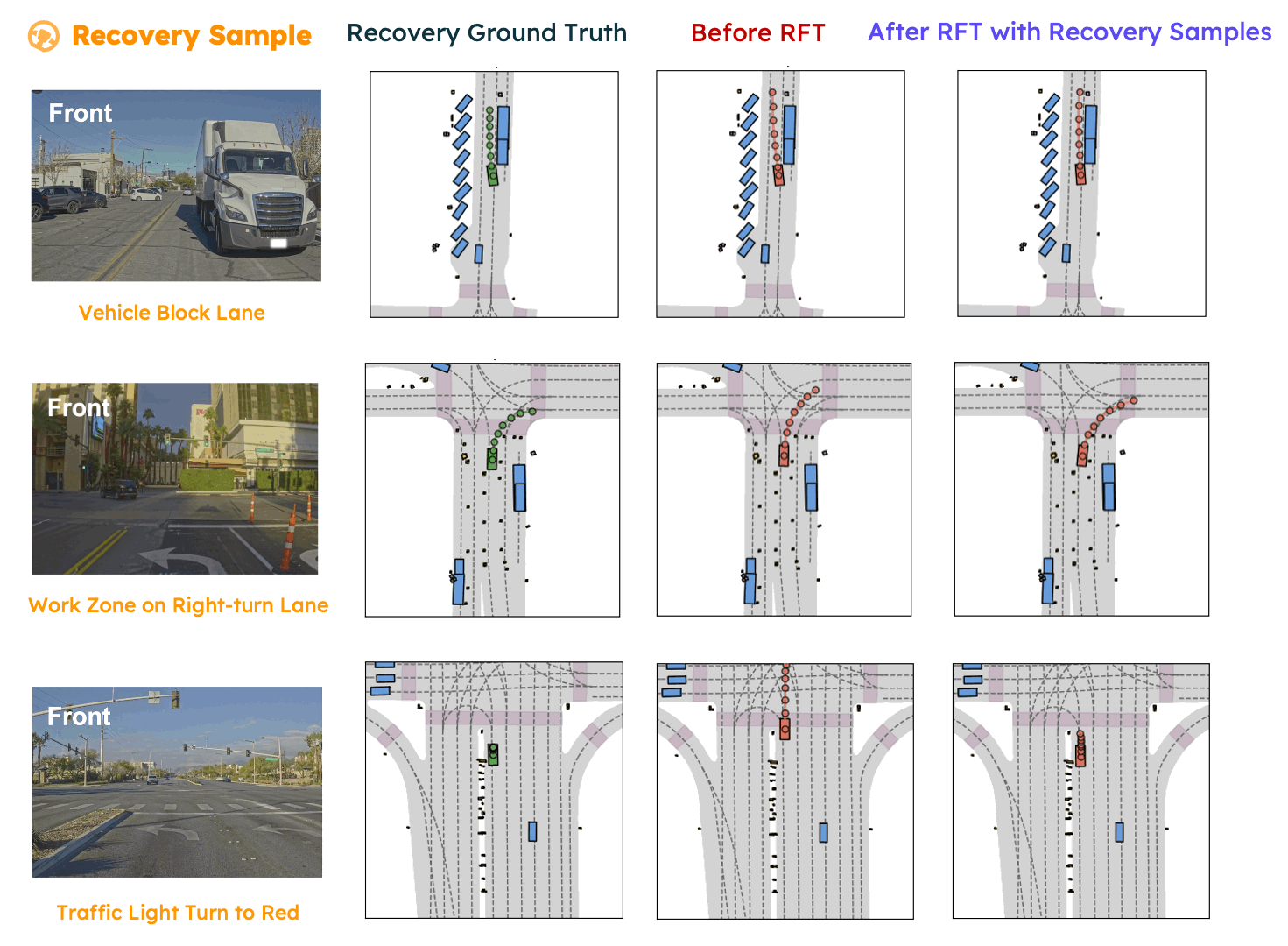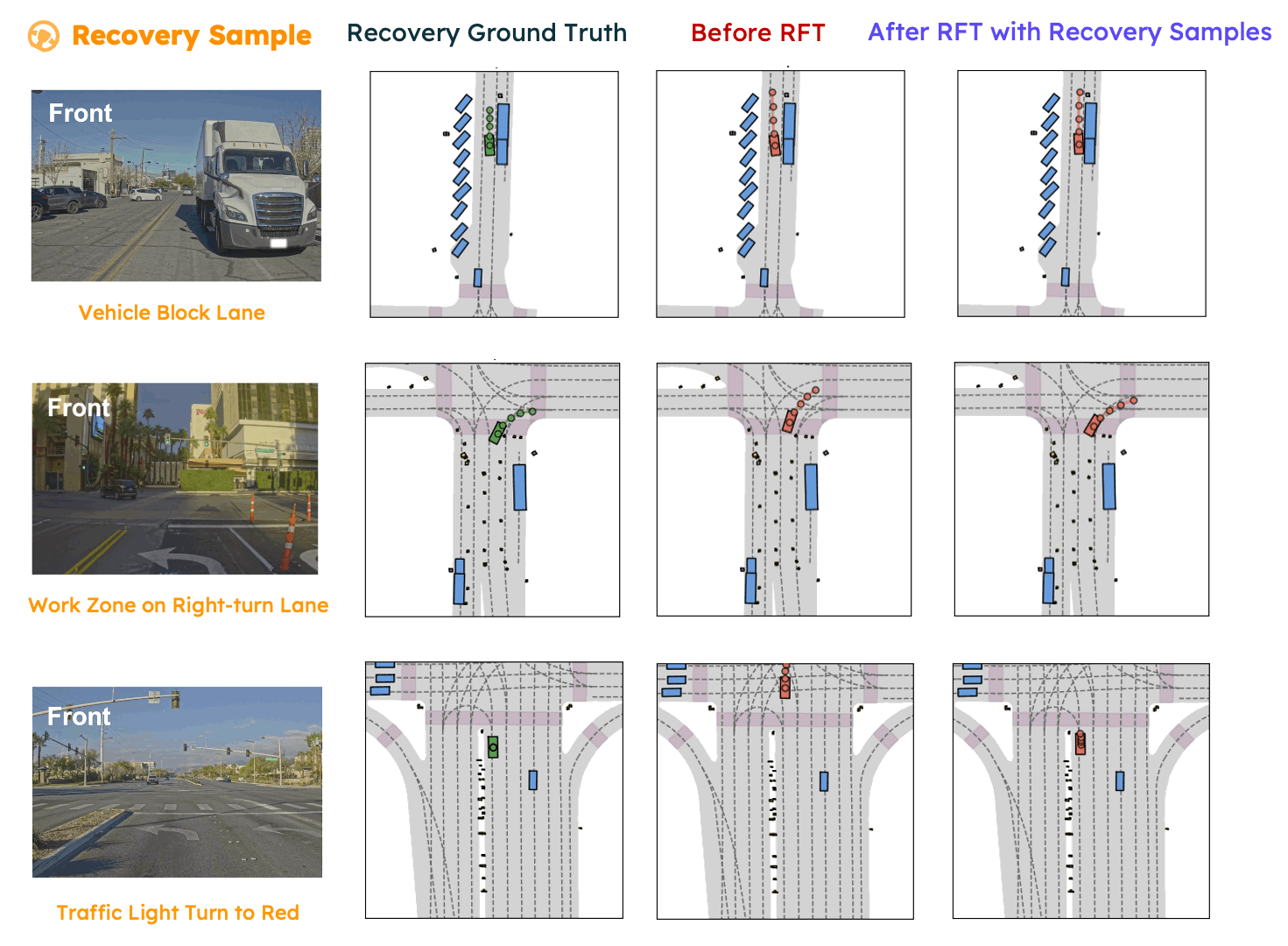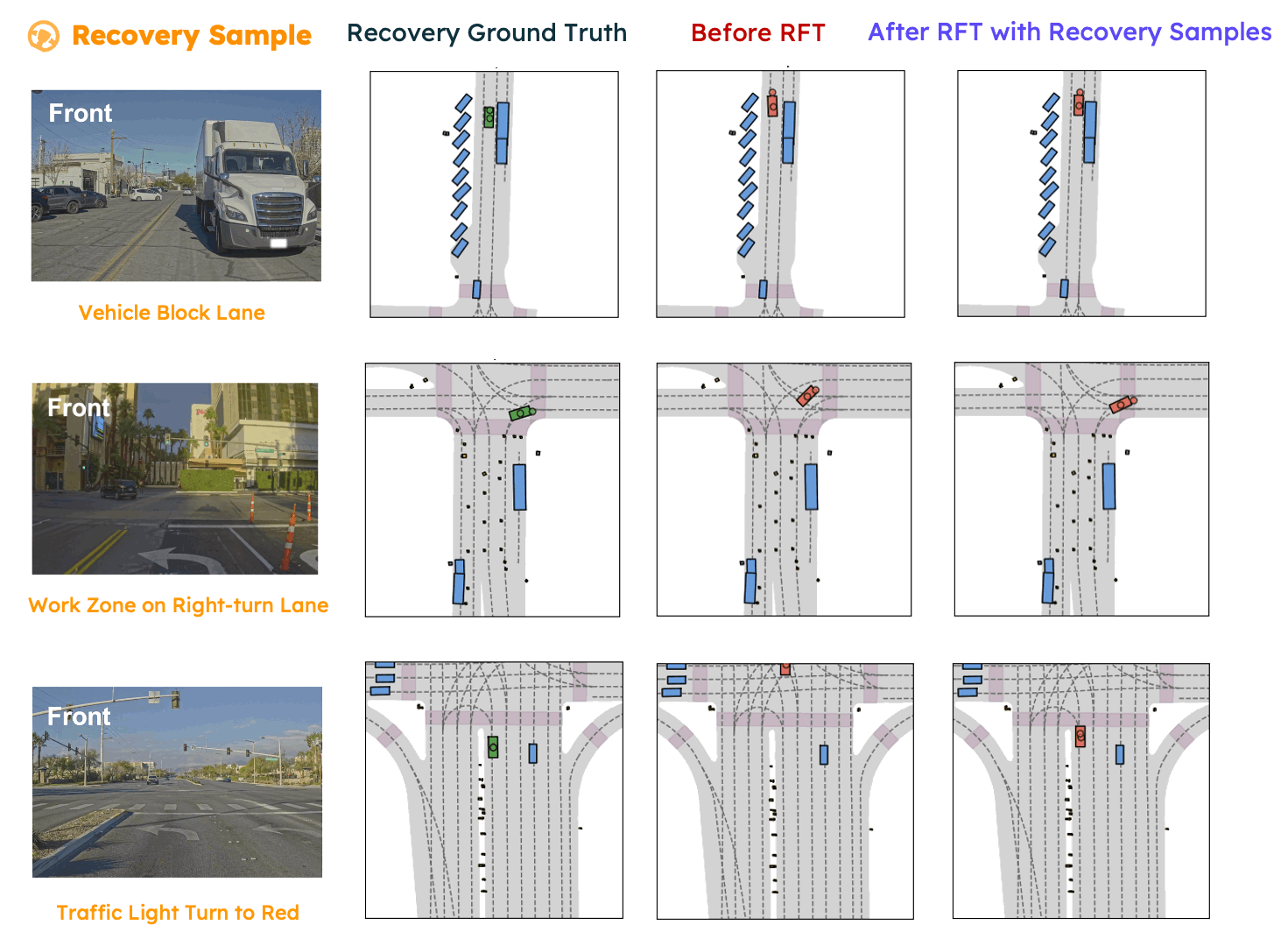
In this paper, we propose SpanVLA, a novel end-to-end autonomous driving framework, integrating an autoregressive reasoning and a flow-matching action expert. First, SpanVLA introduces an efficient bridge to leverage the vision and reasoning guidance of VLM to efficiently plan future trajectories using a flow-matching policy conditioned on historical trajectory initialization, which significantly reduces inference time. Second, to further improve the performance and robustness of the SpanVLA model, we propose a GRPO-based post-training method to enable the VLA model not only to learn from positive driving samples but also to learn how to avoid the typical negative behaviors and learn recovery behaviors. We further introduce mReasoning, a new real-world driving reasoning dataset, focusing on complex reasoning-demanding scenarios and negative-recovery samples.
Extensive experiments on the NAVSIM (v1 and v2) demonstrate the competitive performance of the SpanVLA model. Additionally, the qualitative results across diverse scenarios highlight the planning performance and robustness of our model.
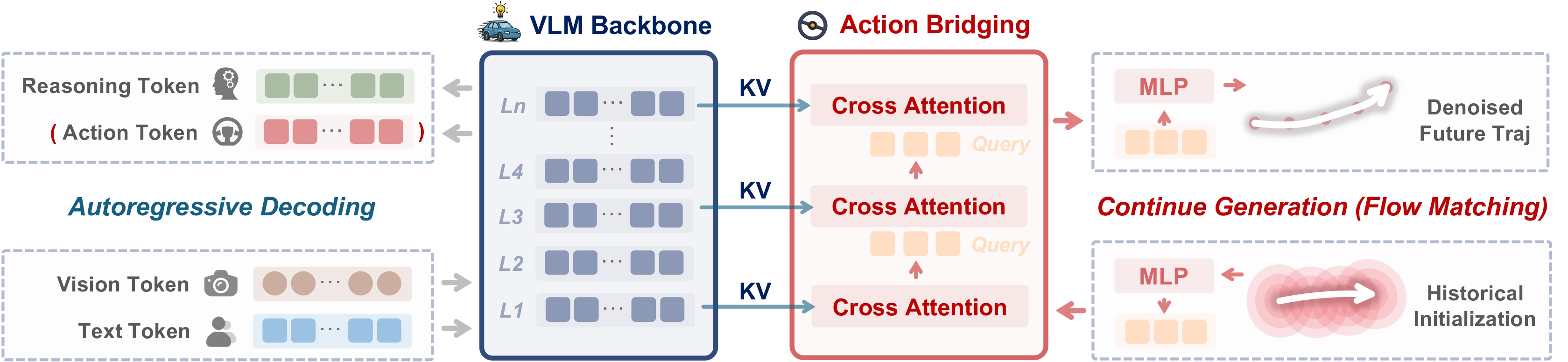
🔗 Two Main Components:
🔍 Training Strategy:
mReasoning includes 30k complex interaction scenarios, and 3k + 3k negative-recovery samples. The dataset is collected from real-world driving scenarios across Las Vegas, Boston, Pittsburgh, and Singapore.

Some complex scenario samples (positive samples) in the mReasoning dataset are shown below
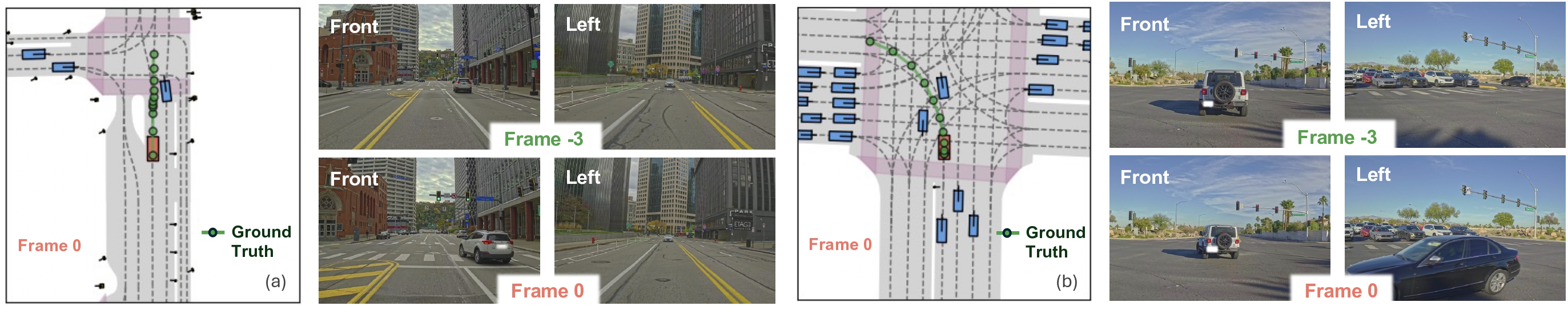
(a) Cut-in scenario: A vehicle from the front-right abruptly cuts in at the intersection. Frame -3 and Frame 0 means the first history frame and the current frame for the camera streams.
(b) Intersection scenario: The ego vehicle has already entered the intersection; despite the red traffic signal, it should yield appropriately and follow the leading vehicle to complete the left turn.
We would like to express our gratitude to Qian Zhu, Haram Kim, and Baoshu Qi for their extensive efforts in data preparation and annotation of the mReasoning dataset. Special thanks also go to Muhammad Taufik Tirtosudiro and Jiong Yang for their support in developing the evaluation pipeline. The authors also thank Nitin Kapania, Sourabh Vora, and Balajee Kannan for their strong support for the project.
@article{zhou2026spanvla,
author = {Zhou, Zewei and Yang, Ruining and Qi, Xuewei and Guo, Yiluan and Chen, Sherry X. and Feng, Tao and Pistunova, Kateryna and Shen, Yishan and Su, Lili and Ma, Jiaqi},
title = {SpanVLA: Efficient Action Bridging and Learning from Negative-Recovery Samples for Vision-Language-Action Model},
journal = {arXiv preprint arXiv:2604.19710},
year = {2026},
}The website design was adapted from nerfies.